THECORRECT UNDERSTANDING OF THE GODHEAD
INTRODUCTION
God, all throughout the Old Testament did not have a body, but appeared to the people in different forms, such as the Burning Bush to Moses, the Cloud by day, and the Pillar of Fire by night, to the children of Israel. Though He sent His angels to many who appeared as men, but no one ever saw God in physical form until Jesus Christ was born. John 1:18 says, “No man hath seen God at any time; the only begotten Son, which is in the bosom of the Father, He hath declared Him”.
GOD IS A SPIRIT
The Scripture states that, “God is a Spirit; and they that worship Him, must worship Him in Spirit and in Truth” (John 4:24). In Isaiah 43 and 45, we can read that God the Father said that He alone is God... "And [there is] no God else beside me; a just God and a Saviour; [there is] none beside Me."(Isa. 45:21) "Before Me there was no God formed, neither shall there be after Me. I, [even] I, [am] the LORD; and beside me [there is] No Saviour." (Isa. 43:10-11)
In these scriptures we can clearly see that there is only one God, (not two or three as others believe) for in His very First Commandment, Elohim (the self-existing One) solemnly said that "Thou shalt have NO other gods before Me..." (Exo. 20:3)
GOD'S THOUGHTS AND ATTRIBUTESWay back in eternity, before there ever was a star, a moon, or a galaxy, Elohim has eternal thoughts and attributes that He wanted to express and manifest for His own pleasure and glorification. He hath seen all things from the beginning, for He is infinite and all knowing.
Elohim wanted to be God. The word "God" means "an object of worship". But there was no one that worships Him at that time and so He then created the angels first, so that He as God is worshipped and is proclaimed as God almighty.
Elohim wanted to become a Father. Yet how can He be called a "Father" when He Himself has no children? And so in God's mind He wanted to create sons and daughters unto himself so that He could become their Father. Thus, we know that this plan of God was fulfilled and manifested later on. He created Adam and from him He took Eve. It's a type of the church which was taken from the body of Christ, for the Bible says, "we are flesh of His flesh, and bones of His bones."
Elohim wanted to become a Saviour. But you see, how can He become a Saviour when there's no one to be saved in the first place? There has to be a fallen entity first before He could ever display his attributes as a Saviour. We can therefore conclude from this case that God hath foreseen the fall of man and He permitted man to fall from grace in order for God to fulfill His majestic plan of saving them. Man was placed as a "free moral agency" to choose for himself between good and evil. Adam and Eve fell for the wrong choice. But God prepared the solution for sin even before the foundation of the world. Revelation 13:8 tells us that the "Lamb was slain "before" the foundation of the world" to act as an atonement for sin. And God wrote our names (God's elected seed) in the Lamb's Book of Life even before man could ever commit sin. Christ came to redeem these predestinated seed.
Elohim wanted to be a Healer, too. Yet how can He become a Healer when there's nobody sick? There has to be a sickness first before He could be a Healer. Which was first, the sickness or the Healer? We can then conclude from here that sicknesses and afflictions are part of God's permissive will to man in order to show and manifest to mankind His attributes of being a Healer. Psalms 103:2-3 states, "Bless the LORD, O my soul, and forget not all his benefits: who forgiveth all thine iniquities; who healeth ALL thy diseases." Consider the afflictions of Job, blind Bartimaeous, the woman with the blood issue, and more. They just declared the glory and healing power of God and served as testimonials of God's grace through each generation.
God also wanted to manifest Himself as a King, as a Priest, and as a Judge. So there has to be a kingdom set-up, a holy tabernacle set-up, and a judgment bar set up. These are His eternal thoughts and intentions before the foundation of the world, to get glory unto Himself.
Yet God knew that as a Spirit He will never be able to fulfill these plans of his without having a "body" that will act out His plans. For example, it is written in His Law that “Almost all things are by the Law purged with blood; and without the shedding of blood is no remission” (Hebrews 9:22). Redemption requires death. Can a Spirit bleed and die?
It takes BLOOD, therefore, to pay the penalty for sin. Yet no man's blood, no angel, no priest, no animal's blood, was ever worthy to redeem man in his fallen estate. God must do it Himself, for there is no Saviour but Him alone. He must do it in order to show that He alone is the ONLY Redeemer. In Isaiah 45:22, God said, “Look unto Me, and be ye saved, for I AM God, and there is none else.” “Thou shalt know no God but Me; for there is NO SAVIOUR BESIDE ME”. (Hosea 13:4).
God is the only Saviour there is. The key to the whole mystery of the Godhead is this. God knew that He, as God, could not die and bleed in the Spirit, for a Spirit has no flesh and bones. His own law required blood for an atonement.
So in order for God to fulfill His plan of redeeming mankind, He had to put on a veil of flesh, in order to taste death and pay the penalty for His own law, to justify the ungodly. That is to fulfill Romans 3:28, “Therefore we conclude that a man is justified by faith without the deeds of the law.” “For by grace are ye saved through faith; and that not of yourselves: it is the gift of God: not of works, lest any man should boast” (Eph.2:8,9).
THOUGHTS EXPRESSED INTO "WORD"
God, then began to express Himself from eternity, by His spoken Word. Time began when God started speaking. This great Fountain of Spirit which had no beginning or no end, began to express His attributes by the Spoken Word. Out of the existence of the Father went out the "Logos", which was the Word, which was God's "Theophany". It was was a visible body of the great Jehovah God going forth in the beginning. It was called the "Logos", which in the original Greek, means “something spoken; which includes the thoughts of the Speaker".
That Logos was God's "express image". It was God Himself made into Word. That Logos that went out from the great eternal Spirit was called the "Son" of God. It was the only visible form that this Spirit had. And It was a "theophany", which means a celestial body, and that body was like a "man".
Time, then, began when that "Logos" came out of God, as evident in the succeeding scripture. John 1:1-3, "In the beginning was the Word and the Word was with God, and the Word was God. The same was in the beginning with God. All things were made by Him; and without Him was not any thing made that was made” ..And the Word was made flesh and dwelt amongst us.” (John 1:1-3, 14).
From that "theophany" is where man was also created by God, after His own image, which was a "spirit-man":
"And God said, Let US make man in our image, after our likeness: and let them have dominion over the fish of the sea, and over the fowl of the air, and over the cattle, and over all the earth, and over every creeping thing that creepeth upon the earth. So God created man in his [own] image, in the image of God created he him; male and female created he them."(Genesis 1:26,27).
The "Let US make man in OUR own image" in the above verse refers to God the Father (the great Spirit) talking, speaking to His Theophany Body, which was His begotten Son. We can see here that man was created from that pattern, with both spirit and body realms. We were never created from the image of angels.
Rev. Branham taught this: "You will never be an Angel. God made Angels, but God made man. And what God does is off of God, which is as eternal as God is. And man's just as eternal as his Creator, because he was made from eternity. (HEBREWS CHAPTER 5 AND 6, JEFF, IN 57-0908M). "Brother, I'm telling you; I believe in the resurrection. God will speak one of these days, and we'll come forth in His image and in His likeness, men and women, not angels, but men and women. God made Angels; we'll never be Angels. We wasn't made for Angels. Men are made men. God made man. He intends him to be man. It's God's pattern." (EL.SHADDAI.title LA.CA 59-0416)The "theophany", which was the Son, is also what's spoken of in Colossians 1:15-17, which reads: "Who is the IMAGE of the invisible God, the firstborn of every creature: For by Him were all things created, that are in heaven, and that are in earth, visible and invisible, whether [they be] thrones, or dominions, or principalities, or powers: all things were created by him, and for him: and He is before all things, and by him all things consist."
That theophany of God was then made FLESH on earth later on in the Person of Jesus Christ Jesus through the womb of Mary.
Revelation 3:14 speaks of Jesus as the "Beginning of the Creation of God". That is Who the Lord Jesus says He is. But those words don't mean exactly as they sound to us. Just taking them the way they sound has made some people (in fact multitudes of people) get the idea that Jesus was the first creation of God, making Him lower than Godhead. Then this first creation created all the rest of the universe and whatsoever it contains. But that is NOT right. You know that doesn't line up with the rest of the Bible. The words are, "He is the BEGINNER or AUTHOR of the creation of God."
Now we know for a surety that Jesus is God, very God. He is the Creator. John 1:3 "All things were made by Him, and without Him was not any thing made that was made." He is the One of Whom it is said, Genesis 1:1 "In the beginning God created the heaven and the earth". Also it says in Exodus 20:11, "For in six days the Lord made heaven and earth, the sea and all that in them is, and rested the seventh day." See, there is no doubt that He is the Creator. He was the Creator of a FINISHED PHYSICAL CREATION.
Surely we can see what these words mean now. To have any other interpretation would mean that God created God. How could God be created when He, Himself, is the Creator?
GOD MANIFESTED IN FLESH
And thus, God fulfilled His plan of salvation, the fulfillment which is written in 1 Timothy 3:16 which states: “And without controversy, great is the mystery of Godliness, God was manifest in the flesh.”
When was God manifested in flesh? It was when Jesus Christ was born through a woman; without any resulting sexual act but it was God Himself making both hemoglobin and egg cells in the womb of Mary, God Himself taking the form of a man.
Jesus Christ was the FLESH of God, none other than God Himself creating a BODY of His own. That fleshly BODY was called the “SON”, while the SPIRIT indwelling that body was the “FATHER”. Not two Gods now, but God veiling Himself in FLESH. That’s the reason Jesus said "I and My Father are one." (John 10:30). Philip, the apostle, one time said to Jesus (John 14:8-9), “Lord, shew us the Father, and it sufficeth us.” And Jesus answered him saying, “ Have I been with you so long and yet hast thou not known Me, Philip? He that hath SEEN ME hath seen the Father.”
The name "Jesus" means "Jehovah has become our Saviour". Jesus was also called “Emmanuel”, meaning, “God WITH us”, God dwelling with men.
When the Father decided to come down as our Saviour, He put on a robe of flesh and planted Himself, as a seed, in the womb of Mary. This seed was to produce the flesh and blood of the Body He would dwell in as the Son, Jesus Christ. Jesus is God becoming man, to redeem man back to Himself. God could not die in the Spirit because He's eternal. But He had to put on a MASK and ACT the part of death. He did die, but He couldn't do it in His God form. He had to do it in SON form, as a Son of Man on earth.
JESUS, THE IMAGE OF THE INVISIBLE GOD
Apostle Paul says this about Jesus in Collosians 2:9-10: “For in HIM all the FULLNESS of the GODHEAD dwells BODILY, and ye are complete in Him, which is the Head of all principality and power”...”In Whom we have REDEMPTION through His BLOOD, even the forgiveness of sins : Who is the IMAGE of the INVISIBLE GOD... And He is before all things, and by Him all things consists” (Collosians 1:14,15,17).
JESUS, therefore, is the EXPRESS IMAGE of the unseen God, God creating a FLESH-BODY of His own. And man could have never seen God except through Jesus Christ, the FLESH of God.
THREE DISPENSATION OF THE ONE GOD
“God ABOVE Us” - that’s how God was known in the Old Testament, in the Fatherhood dispensation. God dwelling in the heavenlies, where no man could ever touch Him.
When the the time for the Sonship dispensation came, fulfilling the prophesy of Isaiah 9:6 which says, “For to us a child is born, for to us a SON is given: the government shall be upon His shoulder; and His Name shall be called Wonderful, Counselor, Mighty GOD, and everlasting FATHER, Prince of Peace”, these all pertain to the FLESH of God - JESUS, being God Himself becoming Emmanuel, which being interpreted “God WITH us” - God Who can now be touched by the feeling of our infirmities.
It was God also fulfilling Isaiah 53:5, “But He (God) was WOUNDED for our transgressions, He was bruised for our iniquities: the chastisement of our peace was upon Him: and by His stripes we are healed” - all fulfilled and completed at the Cross of Calvary.
In these last days, after Jesus has been resurrected and glorified, God has sent us back His Holy Spirit, the Comforter, to indwell every believer. Thus, we are now living in the HOLY GHOST Dispensation.
As 1 Cor. 6:19-20 states, “What? Know ye not that your body is the TEMPLE of the Holy Ghost which is IN YOU, which ye have of God, and ye are not your own? For ye are bought with a price: therefore glorify GOD IN YOUR BODY, and in your spirit which are God’s.”
THE SPIRIT OF JESUS IN THE CHURCH
JESUS is that self-same Holy Spirit; as He has attested in John 14:18, saying, “I will not leave you comfortless, “I“ (Personal Pronoun) WILL COME TO YOU.” “I will be with you, even IN YOU until the end of the world.” Galatians 4:6 states this, too, “And because ye are sons, God has sent forth the SPIRIT of His SON into your hearts, crying Abba, Father.”
Jesus’ own Spirit is now “God IN Us”, the “Hope of Glory” (Colossians 1:27). It is the SELF-SAME GOD all the time, never changing His power, just changed His form from the heavenly to the earthly, and then back again as the Great Spirit, after having fulfilled His great redemptive story.
He was “GOD ABOVE US” in His Fatherhood dispensation; “GOD WITH US” in His Sonship dispensation; and now “GOD IN US” in the Holy Spirit dispensation.
Jesus said, “ I AM ALPHA AND OMEGA, the Beginning and the Ending, saith the Lord, Which IS, WHICH WAS, and WHICH IS TO COME, THE ALMIGHTY” (Rev.1:8) Not three persons in One God but ONE GOD in three dispensations.
JESUS IS BOTH MAN AND GOD
Jesus, talking to the Jews one day, said, “Your father Abraham rejoiced to see my day: and he was glad.” Then said the Jews unto Him, ‘thou art not yet fifty years old and hast thou seen Abraham?’ Jesus said unto them, “Verily, verily, I say unto you, before Abraham was, I AM” (John 8:56-58).
Who was the great “I AM”? Remember the burning fire that talked with Moses on the holy mountain? That was the “I AM”, the self-same Jesus speaking to the Jews. They could not see that Jesus was their own God VEILED IN FLESH.
"The Jews answered him saying, “For a good work we stone thee not; but for blasphemy; and because that Thou, being man, makest Thyself God” (John 10:33). They really failed to see that He was the Emmanuel - both MAN and GOD. Jesus also is the WORD that became FLESH and dwelt amongst us (John 1:1,14).
JESUS certainly was a man weeping at the grave of Lazarus. But when He shouted, “Lazarus, come forth!”, and a dead man, four days and stinking, arose and lived again - that was more than a MAN! Who can raise the dead but God alone.
He was a man hungry that night looking on a tree for something to eat. But when He took five bread and two fishes and feed five thousand - that was more than a man. That was the creator, JEHOVAH!
He was a man laying on the ship that night, tired and asleep, while the waves come up. But once he arose and rebuked the winds and the waves and said, “Peace be still!”. That was more than a man. That was God Who can control all nature.
It was a man crying for mercy at the cross, “My God, My God, why hast Thou forsaken Me?” But on Easter morning, when He broke the seals of death, hell and grave, and rose up again and said, “I AM HE that was dead, and behold, I AM ALIVE FOREVERMORE!” Who was that? That was the same God Who also said, “ I have power to lay my life down, and raise it up again” (John 10:18).
JESUS, BACK TO A “PILLAR OF FIRE”
Let us remember that after Jesus’ death, burial and resurrection, Jesus ascended up into the heavens. And when SAUL of Tarsus was on His road to Damascus to persecute the Christians (Read Acts 9:1-5), a BIG LIGHT, a PILLAR of FIRE struck him, and he asked, “LORD, who are You?” SAUL knew that It was the same Pillar of FIRE that appeared to Moses, but that Pillar of FIRE answered him, saying, “I AM JESUS, whom thou persecutest.” See, He had TURNED BACK, exactly back to THE SAME FORM before He took on a tabernacle of FLESH - the Pillar of FIRE that met Moses in the wilderness.
Remember, It was the SAME Pillar of Fire that came to PETER that night and loosed him out of the prison cell (Read Acts 12:5-7).
That SAME Pillar of Fire (Cloven Tongues of Fire) appeared on the Day of PENTECOST and set on each of those at the upper room, dividing Himself, giving part of His Spirit among His church (Acts 2).
Peter declared in Acts 2:36, “Let all the house of Israel know assuredly that God hath made that SAME JESUS, whom ye have crucified, BOTH LORDAND CHRIST”. There He is - LORD (Fatherhood), JESUS (Sonship), CHRIST (Anointed Holy Ghost) - The LORD JESUS CHRIST, the complete manifestation of the ONE TRUE GOD.
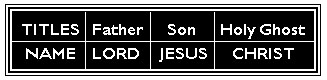
The entire Bible does not say a thing about a First or Second or Third Person in a ONE GOD. The mystery is found in 1 Timothy 3:16: “And without controversy, great is the MYSTERY of Godliness, GOD was manifest in the FLESH, justified in the Spirit, seen of angels, preached unto the Gentiles; believed on in the world, received up into glory”. The ONE TRUE GOD was manifest in the FLESH. That’s how SIMPLE it is. GOD CAME IN A HUMAN FORM. That didn’t make Him another God. He was GOD, THE SAME GOD.
If you cannot accept this TRUTH of the Godhead, but refute it, Jesus said that you are still living in SIN; for He said in John 8:24, “For if ye believe NOT that I AM HE (God), ye shall die in your sins”. “He that believeth not the SON shall not see life; but the wrath of God abideth on him” (John 3:36).

JEHOVAH of the Old Testament is JESUS of the New Testament. That is the great MYSTERY of the Godhead. NOT THREE GODS, but THREE DISPENSATIONS and three OFFICES of the same ONE GOD. Never can we find any Scripture that declares that there are THREE GODS in the Holy Writ. If you do, you are breaking the First Commndment which says, “I alone am GOD, thou shalt have no other Gods before Me.” GOD Himself declared in Isaiah 45:21 that, “There is NO GOD BESIDE ME; a just God and Saviour, THERE IS NONE BESIDE ME.”
JESUS confirmed this truth in Mark 12:29 saying, “The first of all the commandments is, Hear, O Israel; The Lord our God is ONE LORD”.
The whole thing was JEHOVAH GOD condescending Himself from His heavenly estate to an earthly body He called JESUS, fulfilling His sovereign purpose of becoming Saviour, Redeemer and Healer by shedding His OWN BLOOD as the Lamb of God who takes away the sins of the world.
”Of Whom as concerning the FLESH, CHRIST came, Who is OVER ALL, GOD Blessed Forever” (Romans 9:5). AMEN.